Clean Architecture on iOS
21 Sep 2021
This is a continuation of the Clean Code on iOS post, going into the topic of Clean Architecture.
1. Traits of a Clean architecture
There are different variations of architectures that are considered clean, but they all have the following characteristics:
-
Independent of frameworks
The architecture does not depend on the existence of some library of feature-laden software. This allows you to use such frameworks as tools, rather than forcing you to cram your system into their limited constraints.
-
Testable
The business rules can be tested without the UI, database, web server, or any other external element.
-
Independent of UI
The UI can change easily, without changing the rest of the system. A web UI could be replaced with a console UI, for example, without changing the business rules.
-
Independent of the database
You can swap out Oracle or SQL Server for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
-
Independent of any external agency
In fact, your business rules don’t know anything at all about the interfaces to the outside world.
2. Onion-layer diagram
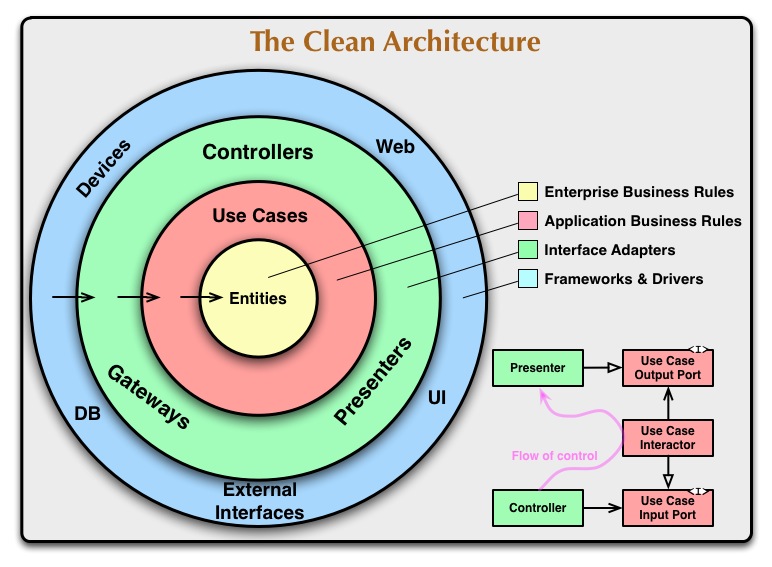
- Enterprise Business Rules represented by Entities
- agnostic of app
- apply to the entire business domain
- have no dependencies
- App Business Rules represented by Use Cases or Interactors
- apply to the application domain
- can depend on Entities
- Interface Adapters: Controllers, Presenters, Gateways, …
- depend on Use cases / Interactors
- Frameworks and drivers: Devices, DB, Web, UI, …
- depend on the rest of the system
NOTE: The arrows (dependencies) always point inward, so the frameworks and drivers depend on the rest of the system, but nothing else depends on them.
3. SOLID Principles
3a. Single Responsibility Principle
A module should have one, and only one, reason to change.
can be rephrased as
A module should be responsible to one, and only one, user or stakeholder.
The simplest definition of a module is a source file.
Why is SRP important:
- leads to small components
- that are easy to read and composable
- avoid conflicts
SRP is different than the lower level principle of refactoring large functions into smaller ones (aka a function should do one thing).
The best way to understand this principle is by lookign at the symptoms of violating it.
Symptom 1 - Accidental Duplication
Let’s imagine an Employee class with 3 methods: calculatePay, reportHours and save.
This class violates the SRP because those 3 methods are responsible for 3 very different actors:
calculatePayis specified by the accounting department, which reports to the CFOreportHoursis specified and used by the HR department, which reports to the COOsaveis specified by the DBAs, who report to the CTO
By putting the source code for these three methods into a single Employee class, the developers have coupled each of these actors to the others. This coupling can cause the actions of the CFO’s team to affect something that the COO’s team depends on.
Let’s assume the calculatePay function and the reportHours function share a common algorithm for calculating the non-overtime hours. The developers will naturally extract that common algorithm into a function regularHours called by both calculatePay and reportHours. When one team (for example the CFO’s team) needs to change the regularHours algorithm, they will affect (and possibly break) the reports the COO’s team is generating.
Symptom 2 - Merges
Merges usually happen in source files that contain many different methods, especially likely if they are responsible for different actors.
For example, the CTO’s team of DBAs wanting to change the schema of the Employee table and the COO’s team of HR clerks want to change the hours report formatting. This means at least 2 developers will make changes to the same file at the same time, probably resulting in a conflict that requires a merge.
Merges are risky affairs, even if we now have tools that handle some cases, we will still end-up with having to resolve conflicts. Unless we really understand what the other team changes are, there’s a good chance we won’t resolve the conflicts properly and introduce issues.
Solutions
There are many different solutions to this problem. Each moves the functions into different classes.
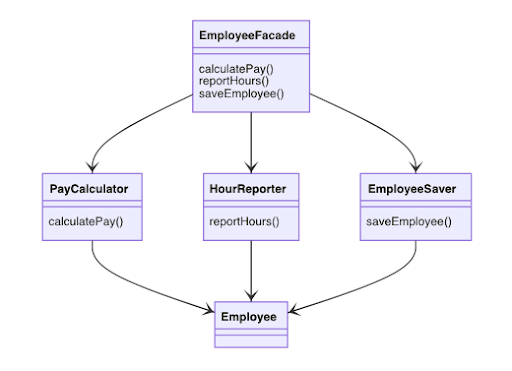
The simplest and most obvious one is to separate the data from the functions. So we create the Employee Data, PayCalculator, HourReporter and EmployeeSaver classes, now the last 3 classes that have encapsuled different pieces of logic are separated from each other.
The downside is that now developers need to instantiate and track all 3 classes. A common solution for this dilemma is to use the Facade pattern by creating an EmployeeFacade that will act as a proxy to each of the dedicated classes.
3b. Open / Closed Principle
A system should be open for extension but closed for modification.
OCP is interconnected with SRP and DIP. When we make sure each class has a single responsibility (SRP) and we make it depend on abstractions instead of concrete types (DIP), OCP quickly follows. Now it’s easy to create new implementations of the abstractions and inject them without having to change the initial class.
OCP is gained by following all the other principles.
Adding new features should be done by adding code / components and changing very little of the existing ones.
Why is OCP important:
- makes the system changeable and testable
- keeps changes contained to one part of the system
Example 1
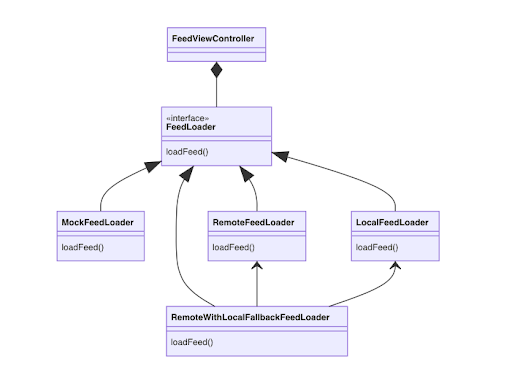
Classic example: we want a screen that displays a list of feed items.
FeedViewController depends on an abstraction FeedLoader. We can have as many implementation as we want:
- at first, mock with dummy data
- remote that fetches the data from the network
- local that loads from local storage
- even a composed remote with fallback on local variant
We can compose the FeedViewController with any of them, while it remains closed for modifications, but open for future extensions.
Example 2 - Enums
Enums break OCP because the client code needs to be updated on every change to the enum.
The Router code is coupled with the current enum cases and is also a dependency magnet, as it references 3 concrete types.
enum DeeplinkType {
case home
case profile
case settings
}
protocol Deeplink {
var type: DeeplinkType { get }
}
class SettingsDeeplink: Deeplink {
let type: DeeplinkType = .settings
func executeSettings() {
// Presents the Settings Screen
}
}
class Router {
func execute(_ deeplink: Deeplink) {
switch deeplink.type {
case .home:
(deeplink as? HomeDeepLink)?.executeHome()
case .profile:
(deeplink as? ProfileDeepLink)?.executeProfile()
case .settings:
(deeplink as? SettingsDeeplink)?.executeSettings()
}
}
}
Using polymorphism makes the Router agnostic of which Deeplink type is it really handling.
Router is closed for modification but open for extension - we can easily add or remove Deeplink implementations without affecting any of the existing code.
3c. Liskov Substitution Principle
Derived classes must be substitutable for their base classes.
Any of MockFeedLoader, RemoteFeedLoader, LocalFeedLoader, … can be used and FeedViewController must work just fine.
Another example: UIPageViewController or UINavigationController work with any APIs that require a UIViewController (because they subclass it).
Why is LSP important? It Allows composing the components in any way we want / need.
3d. Interface Segregation Principle
Make fine grained interfaces that are client specific.
Don’t make clients depend on details they don’t need!
Why is this principle important:
- We end up with smaller interfaces which are composable
- Less code dependencies, especially when they are not needed
A common violation of ISP is creating interfaces with many functions, some optional or unneeded by their clients.
One reason for wanting segregated interfaces is to avoid source code dependencies that are not needed (thus requiring more time to compile and the need to redeploy a bunch of modules on a very small change to just one of them).
Example
protocol GestureProtocol {
func didTap()
func didDoubleTap()
func didLongPress()
}
Splitting a 3 methods GestureProtocol into 3 individual ones, thus allowing clients to conform to 1, 2 or all those protocols without having to add empty method implementations. Also, a class like MyButton can have different properties for each action type (i.e. a tapHandler property of type TapProtocol and a doubleTapHandler property of type DoubleTapProtocol).
protocol TapProtocol {
func didTap()
}
protocol DoubleTapProtocol {
func didDoubleTap()
}
protocol LongPressProtocol {
func didLongPress()
}
class MyButton: UIButton {}
extension MyButton: TapProtocol {
func didTap() { ... }
}
extension MyButton: DoubleTapProtocol {
func didDoubleTap() { ... }
}
We can implement those protocols in multiple classes or just one, but MyButton is agnostic of those details.
Counterexamples
Apple’s frameworks often break ISP by having protocols like UITableViewDataSource or UITableViewDelegate with many methods not needed by most of their clients.
Also, they mix together multiple concepts like data source, prealoading, styling, …
3e. Dependency Inversion Principle
Depend on abstractions, not on concretions.
High-level modules should not depend on low-level modules both should depend on Abstractions. (Abstractions should not depend upon details. Details should depend upon abstractions).
We apply DIP to most of our dependencies, especially volatile ones.
Why is DIP important:
- The system is easy to compose diferently
- Low coupling (as we are not bound to concrete types)
There are always cases where we will need to depend on concrete types - can’t make everything into an abstraction. No problem, refactor later.
One very useful application of DIP is to protect our business code from (3rd party) frameworks. Instead of making our code depend on a framework, we create an abstraction and depend upon it. Then the framework will conform to that abstraction, thus inverting the dependency (Inversion of Control).
protocol FeedLoader {
typealias Items = [FeedItem]
typealias Result = Swift.Result<Items, Error>
func loadFeed(@escaping (Result) -> Void)
}
class FeedViewController: UIViewController {
private let loader: FeedLoader
init(loader: FeedLoader) {
self.loader = loader
}
override func viewDidLoad() {
super.viewDidLoad()
...
let items = loader.loadFeed()
...
}
}
// URLSession based loader
class RemoteFeedLoader: FeedLoader {
// ...
}
// or, even an Alamofire based loader
import Alamofire
extension SessionManager: FeedLoader {
// ...
}
4. Composition over inheritance
Inheritance
Inheritance: “is a” relationship.
Inheritance is the highest form of coupling.
Inheritance breaks encapsulation (allows subclasses to access internal details).
The compilation time and run time for inheritance is bigger, because of virtual tables.
Inheritance is resolved at compile time.
Composition
Composition: “has a” relationship.
Composition is resolved at runtime (you can compose your types differently depending on platform / environment / …).
To achieve low coupling, prefer composition.
This doesn not mean avoid polymorphism (which is a strong programming tool), but rather separate responsibilities into small entities that are composed, also keeping them clean of inherited behavior / interface.
// inheritance
class Device {
let name: String
let operatingSystem: String
}
class Smartphone: Device {}
class Computer: Device {}
// composition
protocol SystemProtocol {
var operatingSystem: String { get }
}
protocol Nameable {
var name: String { get }
}
struct Smartphone: Nameable, SystemProtocol {
var name: String
var operatingSystem: String
}
struct Camera: Nameable {
var name: String
}
5. The Main component aka Composition Root
In every system, there is at least one component that creates, coordinates, and oversees the others. We call this the Main Component or, it’s also known as the Composition Root pattern.
The Main component is the ultimate detail - the lowest-level policy. It’s the initial entry point of the sytem. Nothing, other than the operating system, depends on it. It’s job is to create all the Factories, Strategies, and other global facilities, and then hand control over to the high-level abstract portions of the system.
You can have multiple Main components: one for each configuration, platform or target.
The Composition Root is made of many components (Factories, Adapters, Decorators, …).
Why is the Composition Root important?
- It’s where we define how our system should operate (depending on the conditions)
- We can deal with low level concepts here (current configuration, platform, device vs simulator, target, …)
6. Frameworks are just details
As the Clean Architecture “onion layers” diagram shows, frameworks live at the outer boundary of the system because they are just details. Clean systems should not depend on one or more frameworks becase:
- coupling the business code with framework details makes it harder to write, read and test
- just think about frameworks that ask you to subclass their classes
- the frameworks often change with a different agenda than our project’s
- if the system is coupled with the frameworks, this change is very hard to do
- they should allow us to switch between one framework to another
Examples:
- you should be able to easily change your data storage from in memory, local file storage,
UserDefaults,Keychain,CoreData,SQLite,Realm, … or a combination of them - changing the UI of the app should be easy and require just changes to the UI layer: from
UIKittoSwiftUIor even a simple Command-Line tool without UI - functional / reactive frameworks (
Combine,RxSwift, … ) should be interchangeable and decoupled from the business layers - used only in theCompositionRootbecause of the way they offer out-of-the-box patterns for Adapters / Factories / … - same for networking:
URLSession,Alamofire,AFNetworking,Moya, …
Postpone the decision about which framework / library to use for as much as possible - so you have as much info as possible.
You can use test doubles (mocks or stubs) and you have a low coupling with the actual framework.
7. Handling many 3rd party dependencies
It’s become very normal that iOS projects have a lot of dependencies, especially 3rd parties.
-
We need a networking component, but not sure what we need from that component? No problem, just add a 3rd party.
-
We want to do “analytics”? Sure, add a few more 3rd parties.
- Here’s a cool utility belt library - add it!
- Need a draggable table view cell? Of course there’s a library for that.
Before you know it, your project has a dozen of those dependencies, most likely through different dependency management systems (manual, git submodules, SPM, CocoaPods, Carthage), it takes a large amount of time to clone the project and build it.
A few problems with this approach:
- you’re adding a lot of uncontrollable risks: each library has it’s own roadmap, hidden issues, …
- what do you do when a 3rd party project is abandoned or doesn’t fix the most outstanding issues you have?
- having so many dependencies + a lot of them are not designed for a modular and testable integration results in very hard to test code
I recommend you:
- limit the number as much as possible
- postpone the decision
- protect from them by inverting the dependencies and make the 3rd parties depend on your code.
8. UI layer patterns - a classical iOS debate
MVC, MVVM, MVP, VIPER are just design patterns for the UI layer. They don’t solve the problem of who should handle many other responsibilities like: business rules, data access and storage, notifications, navigation and deeplinking, … Evem though our community is constantly debating which pattern is best and new ones keep coming out, there’s hardly any evidence for it. Indeed, certain patterns are better matches for specific constraints:
- for example, MVC is better suited for
UIKitcomponents as they are already built around theUIViewControllersubtypes - MVVM seems to fit better when working with
SwiftUI

8a. The issue of massive components

But none of those patterns will protect us from the problem of Massive components. Massive View Controller can quickly become Massive View Model or Massive View Presenter. Clean architecture principles help us better separate our code into components and avoid this issue.
9. Cross-cutting concerns
Examples: threading, logging, authentication, analytics, security …
Those concerns are usually spread through the codebase and they are duplicated most of the time.
Example - threading
class MainQueueDispatchDecorator: FeedLoader {
private let decoratee: FeedLoader
init(decoratee: FeedLoader) {
self.decoratee = decoratee
}
func load(completion: @escaping (FeedLoader.Result) -> Void) {
decoratee.load { result in
if Thread.isMainThread {
completion(result)
} else {
DispatchQueue.main.async {
completion(result)
}
}
}
}
}
When composing the FeedViewController, we can pass an instance of MainQueueDispatchDecorator as a FeedLoader, while keeping all the FeedLoader implementations clean of threading.
Example - analytics / logging
Instead of having each ViewModel do analytics or logging, we can decorate the ViewModel with analytics / logging behavior, keeping it clean of this cross-cutting concern.
10. References
- iOS Lead Essentials program - Online program meticulously thought out for iOS developers who want to become world-class senior developers and be part of the highest-paid iOS devs in the world. Focuses on key concepts like Swift, TDD, BDD, DDD, Clean Architecture, Design Patterns, Git, Automation, CI/CD, and Modular Design.
- The Clean Coder by Robert C. Martin
- Dependency Injection: Principles, Practices, and Patterns by Mark Seemann and Steven van Deursen
- Test Driven Development: By Example by Kent Beck
- Working Effectively with Legacy Code by Michael C. Feathers
- Design Patterns by Gamma, Johnson, Vlissides, Helm
- Clean Architecture by Robert C. Martin
- Pro Git by Scott Chacon
Tags: SOLID Clean Architecture
💬 Comments
Post comment using GitHub